@file:DependsOn("/antlr-4.11.1-complete.jar")
@file:DependsOn(".")Structured Lexical Analysis With ANTLR
1 Introduction to ANTLR
1.1 What is ANTLR?
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files. It’s widely used to build languages, tools, and frameworks. From a grammar, ANTLR generates a parser that can build and walk parse trees.
Terence Parr, the author of ANTLR
1.2 Lexical analysis using ANTLR
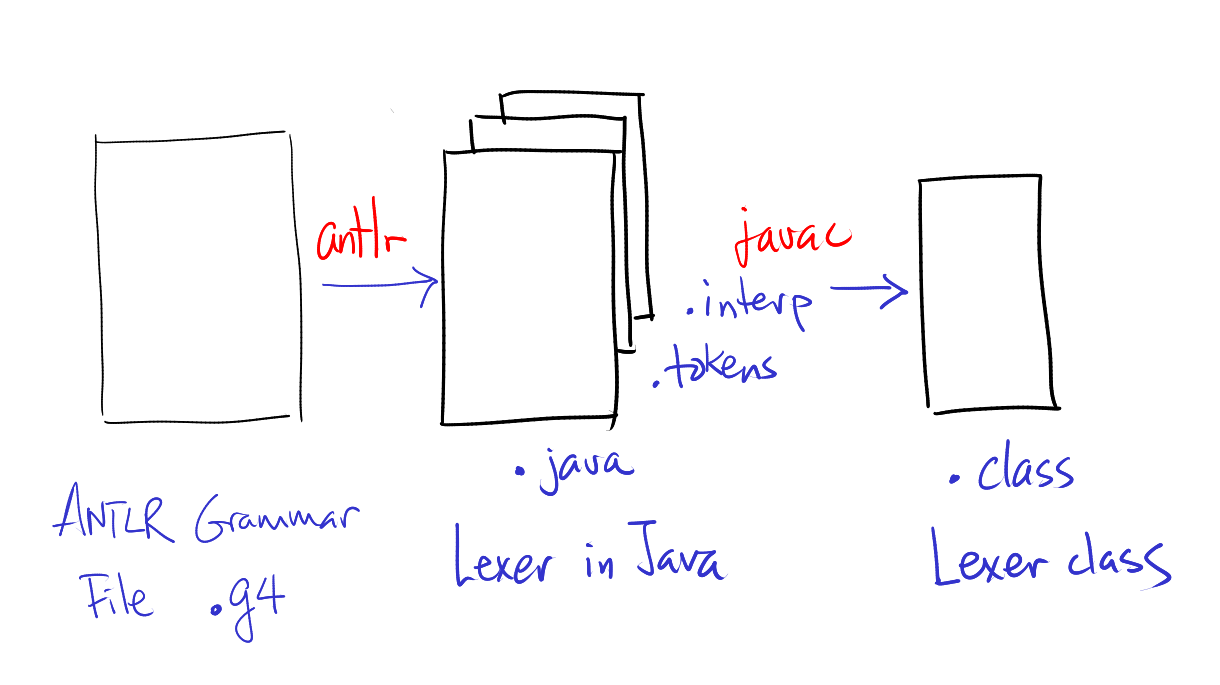
ANTLR can help us with the construction of a lexer class. It requires a lexer grammar file .g4, which is converted to a Java class.
2 Example
2.1 The grammar file
// SampleLexer.g4 lexer grammar SampleLexer; WHITESPACE : [ \t]+; NEWLINE : [\r\n]+; NUMBER : [0-9]+; WORD : [a-zA-Z]+;
2.2 A slightly different syntax
WHITESPACE : ' ' | '\t';
NEWLINE : '\r' | '\n';
NUMBER: ' ('0' .. '9')+;
WORD: (('a' .. 'z') | ('A' .. 'Z'))+;2.3 ANTLR Toolchain
$ java -jar /antlr-4.11.1-complete.jar
ANTLR Parser Generator Version 4.11.1
-o ___ specify output directory where all output is generated
-lib ___ specify location of grammars, tokens files
-atn generate rule augmented transition network diagrams
-encoding ___ specify grammar file encoding; e.g., euc-jp
-message-format ___ specify output style for messages in antlr, gnu, vs2005
-long-messages show exception details when available for errors and warnings
-listener generate parse tree listener (default)
-no-listener don't generate parse tree listener
-visitor generate parse tree visitor
-no-visitor don't generate parse tree visitor (default)
-package ___ specify a package/namespace for the generated code
-depend generate file dependencies
-D<option>=value set/override a grammar-level option
-Werror treat warnings as errors
-XdbgST launch StringTemplate visualizer on generated code
-XdbgSTWait wait for STViz to close before continuing
-Xforce-atn use the ATN simulator for all predictions
-Xlog dump lots of logging info to antlr-timestamp.log
-Xexact-output-dir all output goes into -o dir regardless of paths/packageLet’s generate the lexer Java class.
$ java -jar /antlr-4.11.1-complete.jar ./SampleLexer.g4
$ tree .
.
├── SampleLexer.g4
├── SampleLexer.interp <-- new
├── SampleLexer.java <-- new
└── SampleLexer.tokens <-- newCompiling the code to Java class
$ javac -cp /antlr-4.11.1-complete.jar:. ./SampleLexer.java
$ tree .
.
├── SampleLexer.class <-- new
├── SampleLexer.g4
├── SampleLexer.interp
├── SampleLexer.java
└── SampleLexer.tokens2.4 Using the lexer in Kotlin
import org.antlr.v4.runtime.*val input:CharStream = CharStreams.fromString("hello 123")val lexer = SampleLexer(input)val stream: CommonTokenStream = CommonTokenStream(lexer)val tokens: List<Token> = stream.apply {
this.fill()
}.getTokens()tokens.joinToString("\n")[@0,0:4='hello',<4>,1:0]
[@1,5:5=' ',<1>,1:5]
[@2,6:8='123',<3>,1:6]
[@3,9:8='<EOF>',<-1>,1:9]3 Kotlin + Java + ANTLR
3.1 Directory structure
.
├── Main.kt
├── Makefile
└── my
└── SampleLexer.g43.2 The Makefile
ANTLR = /antlr-4.11.1-complete.jar
CLASSPATH = $(ANTLR):.
lexer:
java -jar $(ANTLR) my/*.g4
app:
javac -cp $(CLASSPATH) my/*.java
kotlinc -cp $(CLASSPATH) ./Main.kt
run:
kotlin -cp $(CLASSPATH) MainKt
clean:
rm -f my/*.class my/*.interp my/*.tokens my/*.java
rm -rf ./META-INF ./*.class3.3 The lexer file
lexer grammar SampleLexer;
@lexer::header {
package my;
}
WHITESPACE : [ \t]+;
NEWLINE : [\r\n]+;
NUMBER : [0-9]+;
WORD : [a-zA-Z]+;The @lexer::header allows us to inject code before the generated lexer class.
3.4 Generating Java source code
$ make lexerThis generates a Java source code that implements a lexer:
// Generated from java-escape by ANTLR 4.11.1
package my;
import org.antlr.v4.runtime.Lexer;
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.Token;
import org.antlr.v4.runtime.TokenStream;
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.atn.*;
import org.antlr.v4.runtime.dfa.DFA;
import org.antlr.v4.runtime.misc.*;
@SuppressWarnings({"all", "warnings", "unchecked", "unused", "cast", "CheckReturnValue"})
public class SampleLexer extends Lexer {
static { RuntimeMetaData.checkVersion("4.11.1", RuntimeMetaData.VERSION); }
protected static final DFA[] _decisionToDFA;
protected static final PredictionContextCache _sharedContextCache =
new PredictionContextCache();
public static final int
WHITESPACE=1, NEWLINE=2, NUMBER=3, WORD=4;
public static String[] channelNames = {
"DEFAULT_TOKEN_CHANNEL", "HIDDEN"
};
...
}3.5 The Kotlin application
import org.antlr.v4.runtime.*
import my.*
fun main() {
val input = CharStreams.fromString("hello 123")
val lexer = SampleLexer(input)
val stream = CommonTokenStream(lexer)
val tokens = stream.apply {
this.fill()
}.getTokens()
.joinToString("\n")
println(tokens)
}3.6 ANTLR Testrig
- Rig: a platform.
- Test rig is a platform for testing.
org.antlr.v4.gui.TestRigis an executable class that tests ANTLR grammars and lexers.
java -cp ... org.antlr.v4.gui.TestRig
java org.antlr.v4.gui.TestRig GrammarName startRuleName
[-tokens] [-tree] [-gui] [-ps file.ps] [-encoding encodingname]
[-trace] [-diagnostics] [-SLL]
[input-filename(s)]
Use startRuleName='tokens' if GrammarName is a lexer grammar.
Omitting input-filename makes rig read from stdinWe can use the testrig to try out a lexer on a given file.
$ java -cp $(CLASSPATH) \
org.antlr.v4.gui.TestRig \
my.SampleLexer \
tokens -tokens \
files/sample.txtHere is a sample output:
[@0,0:4='hello',<WORD>,1:0]
[@1,5:5=' ',<WHITESPACE>,1:5]
[@2,6:8='123',<NUMBER>,1:6]
[@3,9:9='\n',<NEWLINE>,1:9]
[@4,10:14='world',<WORD>,2:0]
[@5,15:15='\n',<NEWLINE>,2:5]
[@6,16:18='456',<NUMBER>,3:0]
[@7,19:19='\n',<NEWLINE>,3:3]
[@8,20:19='<EOF>',<EOF>,4:0]